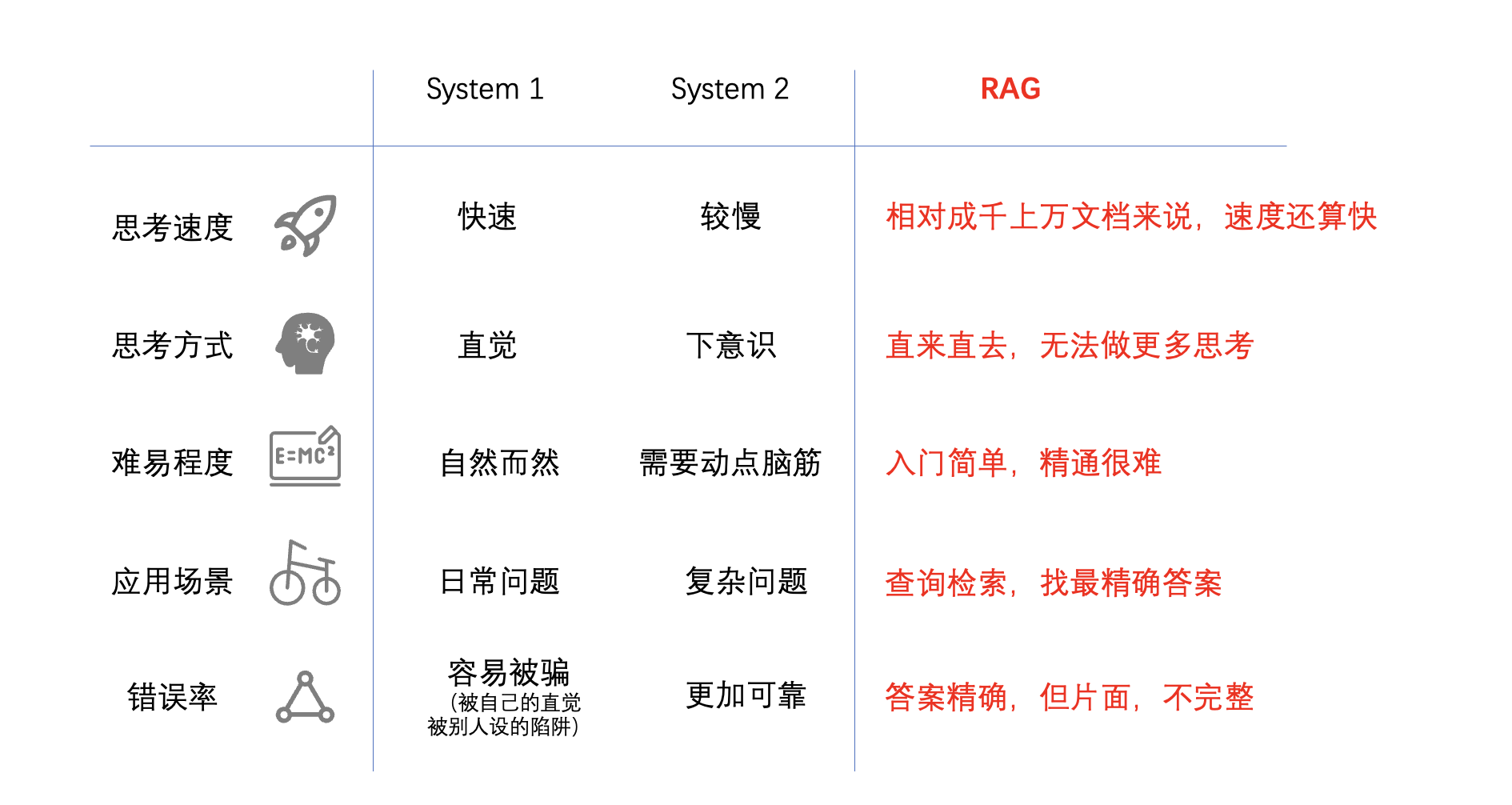
RAG如何才能做到慢思考?
RAG的《思考,快与慢》
土猛的员外
从2023年11月29日开始启动公司(杭州萌嘉网络科技有限公司),到12月中旬开始研发TorchV,第一个对外试用版本终于开始接受试用了。
欢迎企业用户试用,共同探讨AI的企业应用落地。
下面的内容主要分为:
- TorchV Bot产品介绍;
- 有哪些可以说道的特性;
- 如何试用?
- 合作方式;
- 附录1:RAG简要说明;
- 附录2:TorchV Bot操作说明
TorchV Bot是一款基于大语言模型(Large Language Model,后文简称LLM)和检索增强生成(Retrieval-augmented generation,后文简称RAG)技术的人工智能问答机器人,属于TorchV最主要的三款产品(Bot、Assistant和Analyst)中一款。
这是一篇翻译文章,觉得确实很有启发,所以发出来大家一起看看。
我们现在做RAG应用,对于tokens确实很敏感,能省一些是一些吧,但是这篇文章是针对英文的,不知道对于中文支持的怎么样?
我们后面也会真正用起来,会再给大家汇报一下使用效果,或者会发布我们自己的改良方法。
感谢原作者:Iulia Brezeanu,原文和引用在文末。
推理过程是使用大型语言模型时消耗资金和时间成本的因素之一,对于较长的输入,这个问题会更加凸显。下面,您可以看到模型性能与推理时间之间的关系。
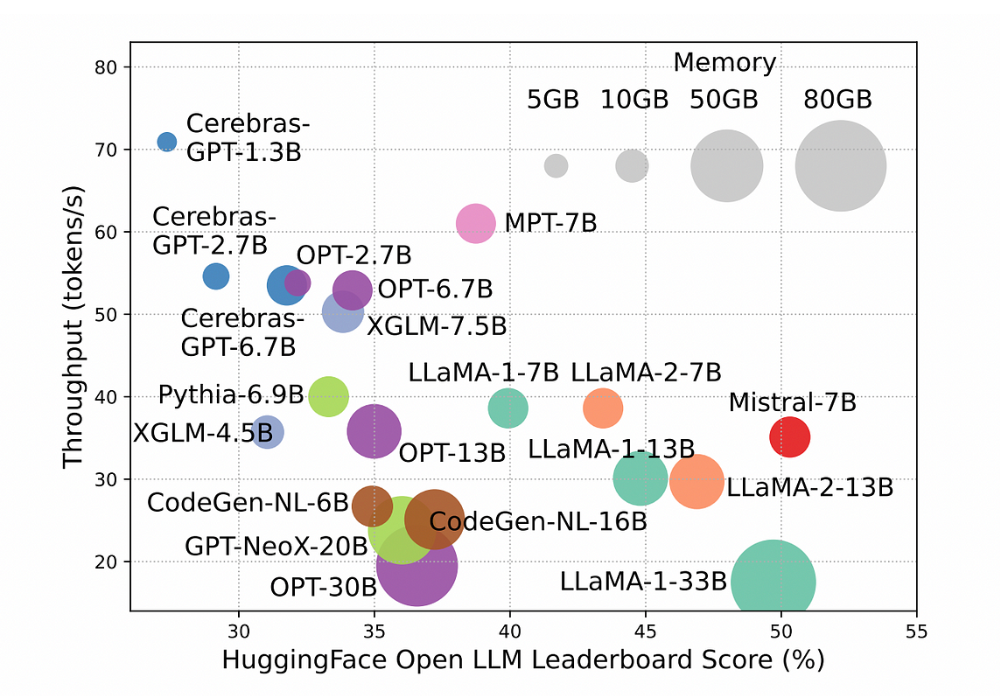
小型模型每秒生成更多的tokens,往往在Open LLM排行榜上得分较低。增加模型参数大小可以提高性能,但会降低推理吞吐量。这使得在实际应用中部署它们变得困难[1]。
提高LLMs的速度并减少资源需求将使其能够更广泛地被个人或小型组织使用。
对于提高LLM的效率,目前大家提出了不同的解决方案来,有些人会关注模型架构或系统。然而,像ChatGPT或Claude这样的专有模型只能通过API访问,因此我们无法改变它们的内部算法。
本文我们将讨论一种简单且廉价的方法,该方法仅依赖于改变输入给模型的方式——即提示压缩。
AI领域最近的风声:2024是RAG爆发年。
对于这些信息,我的理解是这样的:
LLMs属于Infra,属于大厂和已经被资本投资的“AI大厂”们玩的,2023年大部分的投资也都是大额的,聚焦在LLMs这一领域。但是LLMs要找到健康的商业模式,必须与更丰富的业务场景结合起来,就需要大量基于LLMs的应用去拓展市场,不论是toC还是toB。所以到了Q4,有些资本已经在讨论2024年的投资要更加分散,更关注AI原生应用。作为基于LLMs应用支撑技术的RAG,也就必然会被特别关注,我想这就是所谓的2024是RAG爆发年的道理了。
但是今天我不是来讨论RAG的,虽然公众号“土猛的员外”是有很明显的RAG标签的,我今天更想讨论的是AI原生应用(AI-Native App)这个话题:
- 什么是AI原生应用?
- AI原生应用有什么不同之处?
- AI原生应用的猜想
在讲什么是AI原生应用之前,我们可以先来看看电动机在最开始时候的应用。
昨晚和小明在讨论elasticsearch的检索,整整写了三黑板。主要原因是elasticsearch的检索有knn(其实是ann,前面文章有讲过)和bm25两种,如何在不同的场景(针对不同客户)设置不同的boost比例就变得非常重要。昨晚讨论的最终结果是在针对不同的客户(租户)都分别拉出五个参数,便于在面对不同客户场景时可以将检索准确度做到最佳。
可以简单展示一下其中的三个参数:
boost * BM25_SCORE+(1-boost) * KNN_SCORE。也就是说,boost=1,那么就完全用BM25的得分来排序了,以此类推;f_llm;看到O’Reilly的调查好文,翻译转发分享给大家。
本文的主要内容:
- 企业是如何使用生成式AI的?
- 在使用中遇到了哪些瓶颈?
- 企业希望生成式AI可以解决哪些缺陷和差距?
生成式AI是2023年最大的科技故事。几乎每个人都玩过ChatGPT、Stable Diffusion、GitHub Copilot或Midjourney。一些人甚至试用了Bard或Claude.ai,或者在他们的笔记本电脑上运行Llama(或Llama.cpp)。每个人都对这些语言模型和图像生成程序将如何改变工作的本质、迎来奇点、甚至可能毁灭人类有着自己的看法。在企业中,我们看到了从大规模采用,到严格限制,甚至禁止使用生成式AI的风向变化。
现实是什么?我们想知道人们到底在做什么,所以在9月份我们调查了O’Reilly的用户。我们的调查重点是:
本文主要内容:
大模型LLM为什么会有幻觉?
“消灭”幻觉的四个主要方法
幻觉如何检测
在之前我一篇文章比较受欢迎的文章《大模型主流应用RAG的介绍——从架构到技术细节》中提到了大语言模型(LLM)的主要缺点有三点:
这三个问题中,“新鲜度问题”已经基本上被解决了,像GPT-4 Turbo这样的最新大模型已经有类似RAG(Retrieval Augmented Generation,检索增强生成)这样的技术,可以借助外挂快速吸收最新知识(世界知识)。剩下的两个问题,“数据安全”最好的解决方案当然是本地化,敏感数据不上公网才是最安全的。次之的解决方案是使用可信度更高的大模型厂商,他们肯定都有基本的职业操守。当然这不是本文主要讨论的问题。好了,剩下最棘手的就是大模型的“幻觉问题”了,所以今天我们主要来讲讲幻觉,以及如何“消灭”幻觉。
就大语言模型(LLM)本身来说,可能是永远无法消除“幻觉”的,就像Sam Altman说:“幻觉和创造性是等价的”。这个概念我似乎很早就理解了,因为就像生物进化一样,只有不稳定的随机性才能带来的多样性,而多样性才能让物种穿越周期不断进化。
本文重点:
用弹子球机来展示大语言模型的一些内部原理
如何去调整参数,以达到我们想要的模型输出效果
今年5月份的时候我说国内真正使用过ChatGPT的人不超过5%,但是到了11月份,我再和企业、政府等的一些客户交流时,已经很难再碰到整个交谈过程中不说大语言模型(LLM)的了。但是说实话,大部分人对于LLM的了解还是很“新闻”化的,看到了现象但不达本质,往往造成了对LLM的“神化”。所以今天这篇文章,我希望用相对不那么技术化的描述来讲讲LLM的一些原理和概念,让大家对LLM有更近一步了解,也许对大家后面使用LLM及其应用有一定的帮助。
首先做个说明:本文不会讲太多数学公式,我会尽量保证非数学、统计专业的朋友可以看懂。
今年2月份我写过一篇关于GPT的文章《ChatGPT会给文旅行业带来什么改变》,里面提了一下ChatGPT的原理,如下图所示。
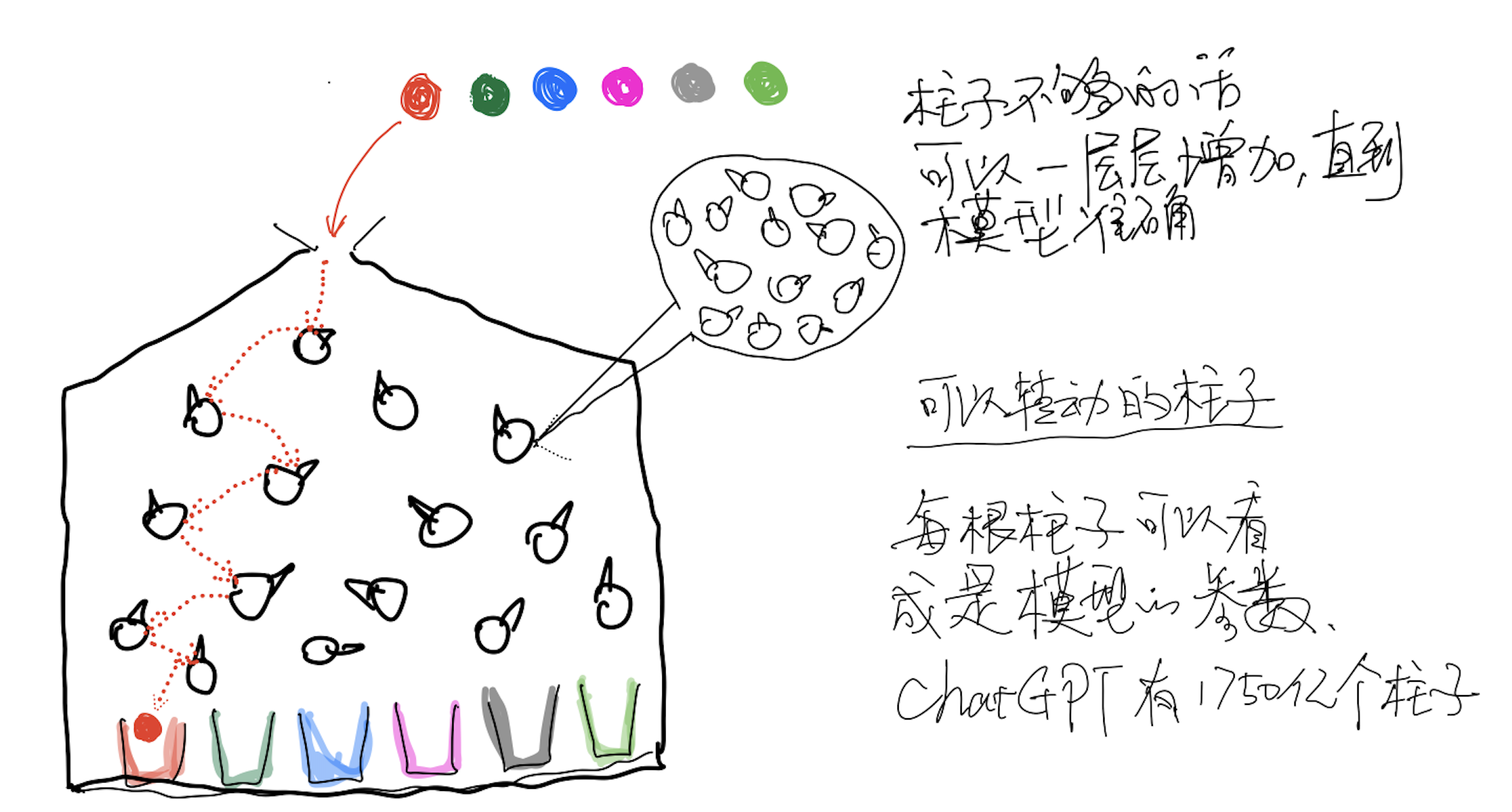
当时说的是假设我们有一个弹子球机器,把各种不同(颜色、重量、尺寸)的球从顶部扔进去,球会和里面的这些柱子(杯子上方的这些圈圈)相碰撞,最终掉下来,落进最下面的杯子里。我们期望机器可以做到”红色的球最终掉进红色的杯子,蓝色球掉进蓝色杯子,依次类推“,我们可以做的事情是调整机器里面的柱子(假设这些柱子表面是不规则的,而且我们可以旋转这些柱子)。
上周算是我正式离职创业的第一周,拜访客户、行业交流、选办公场地、置办办公设备等等,很多时间不在电脑面前,所以上周没更新任何文章。嗯,那就这周补上,发两篇!

今天这篇是上周本来就想写的,就是OpenAI DevDay(开发者大会)之后,基于大模型及相关的创业项目前景如何。
